Crowding
A significant challenge to our ability to see, attend to, and act upon a visual item is the effect of surrounding items. Vision in a cluttered scene is extremely inefficient as we search, often in vain, for the important targets among the unimportant ones, or as we read words on a printed page or computer display. This clutter effect is called crowding and sets the limits on our reading speeds, our ability to pick out dangerous items among harmless ones (target screening at airport security), and our access to important information on our computer screens. We have proposed that crowding is determined by the limits of attentional resolution (He, Cavanagh, Intriligator, Nature, 1996; Intriligator & Cavanagh, Cognition, 2001). The target and adjacent distractors interfere with each other when the smallest region of attentional selection (“window” or “spotlight”) available is not small enough to pick up the target independently of the distractors. Landolt (1896) was the first to show that we cannot individuate or count items that are closely spaced even though we may be able to see them quite well. In this case, the features of all items falling within one selection region are irretrievably mixed. Attentional resolution is very coarse and if our visual resolution were as poor as our attentional resolution, we would be legally blind.
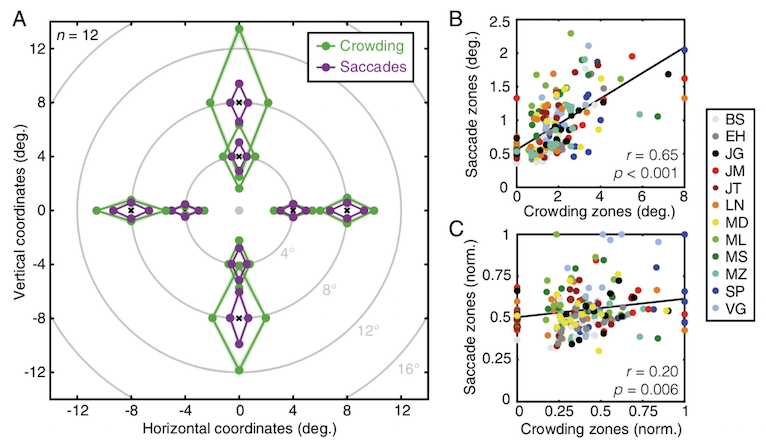
The resolution of attention, like that of spatial vision varies with eccentricity and is worse when the distractors are arrayed radially from fixation than tangentially. This shape of the crowding zone is similar to that for many other aspects of spatial vision, such as the spread of the landing zone for saccades. What is interesting is that the shape of these zones varies from person to person, some people having larger zones on the left vs right or narrower on the top vs the bottom. Most important, there are strong correlations of these idiosyncratic variation across crowding, saccade and more fine grained spatial tasks (Greenwood et al., PNAS 2017). We proposed a “topology of spatial vision,” whereby idiosyncratic variations in spatial precision are established early in the visual system and inherited up to the highest levels of object recognition and motor planning.
Here is a comparison of crowding and saccade error zones. The fovea is indicated as a gray dot with each zone plotted around the location of the target during trials (black crosses). For each location, the size of crowding and saccade error zones is shown for radial and tangential dimensions. On the top at the right, the crowding zones are plotted against saccade error zones with individual data shown in different colors. The black line shows the best-fitting linear regression. On the bottom, the data have been normalized to remove the common effects of eccentricity and radial-tangential anisotropy.